 spark技术分享
spark技术分享
实践|图解AQE的使用
我们都知道,之前的 CBO,都是基于静态信息来对 执行计划进行优化,静态统计信息大家都懂的,不一定准确,比如hive中的catal ...
我们都知道,之前的 CBO,都是基于静态信息来对 执行计划进行优化,静态统计信息大家都懂的,不一定准确,比如hive中的catal ...

目录:一、数据倾斜介绍与定位二、解决方法一:聚合数据源三、解决方法二:提高shuffle操作reduce并行度四、解决方法之三: ...

首发个人公众号 spark技术分享 , 同步个人网站 coolplayer.net ,未经本人同意,禁止一切转载很久之前的& ...
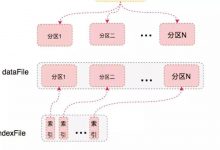
最近深入研究了下 spark shuffle 过程,感觉其中的设计和实现很是有趣,记录下来分享给大家
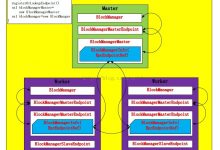
spark 自己的分布式存储系统 - BlockManager
彻底理解 spark 的checkpoint 机制

顾名思义,broadcast 就是将数据从一个节点发送到其他各个节点上去。这样的场景很多,比如 driver 上有一张表,其他节点上运 ...
作为区别于 Hadoop 的一个重要 feature,cache 机制保证了需要访问重复数据的应用(如迭代型算法和交互式应用)可以运行的更 ...
前三章从 job 的角度介绍了用户写的 program 如何一步步地被分解和执行。这一章主要从架构的角度来讨论 master,worker,dri ...
上一章里讨论了 job 的物理执行图,也讨论了流入 RDD 中的 records 是怎么被 compute() 后流到后续 RDD 的,同时也分析了 ta ...
